
Article rédigé avec assistance IA, validé et préfacé par Maxence Méheust.
Make, Zapier, n8n — l'automatisation sans code permet aujourd'hui à une TPE de connecter ses outils et d'éliminer des heures de saisie sans embaucher un développeur. Mais la réalité terrain est plus nuancée que les démonstrations YouTube, et un angle est presque toujours absent du débat : chaque flux que vous branchez en SaaS américain par défaut fait potentiellement transiter votre savoir-faire métier par des serveurs où vous n'avez plus la main. Automatiser oui — mais sans laisser fuir ce qui fait votre valeur.
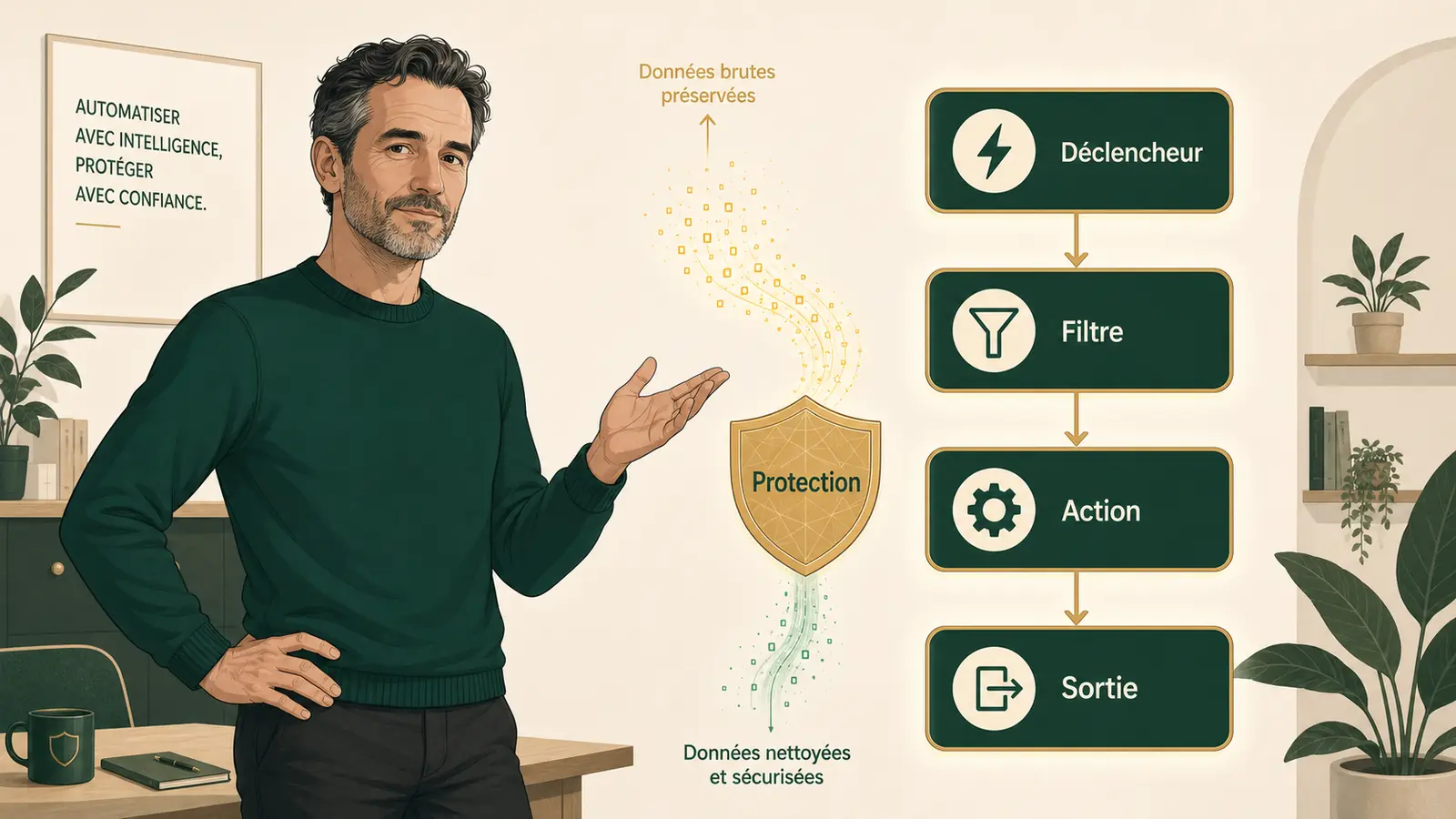
Que permettent vraiment Zapier, Make et n8n en 2026 ?
Ces outils permettent de connecter deux applications et de déclencher une action automatique quand un événement arrive : nouveau client Stripe, formulaire de contact rempli, facture envoyée. Une TPE qui automatise 5 à 10 flux récurrents récupère typiquement 4 à 8 heures par semaine de saisie manuelle, sans ligne de code. Mais la maintenance et le périmètre des données qui transitent restent deux angles morts.
Les déclencheurs simples fonctionnent très bien. « Quand X se passe dans l’application A, faire Y dans l’application B » : nouveau client Stripe vers fiche dans le CRM (gestion de la relation client), formulaire de contact vers e-mail plus tâche, facture envoyée vers ligne ajoutée dans un tableur. Ces cas tournent de manière fiable, sans intervention.
Les flux multi-étapes vont plus loin : conditions, boucles, transformations de données, branchements selon le contenu. Make et n8n gèrent ça nativement. Mais la maintenance devient rapidement chronophage si personne ne fait vivre le flux. Une automatisation oubliée est une automatisation qui finit par tomber en panne silencieusement.
Comment automatiser sans laisser fuir vos données métier ?
Presque tout le monde a pris l’habitude de cliquer « Tout accepter » sur les bandeaux cookies. Le même réflexe inconscient s’étend aux outils d’automatisation : on connecte tout, sans regarder où vont les données. Automatiser sans process, c’est laisser fuir votre savoir-faire dans des serveurs sur lesquels vous n’avez plus la main.
Quand vous branchez un workflow Make ou Zapier, les données transitent par défaut par leurs serveurs américains. Un contrat, une fiche client identifiante, un mail commercial avec votre méthode de pricing — tout cela peut servir à entraîner les modèles d’IA des éditeurs si vous n’avez pas regardé les conditions. Cookies-réflexe étendu aux flux pro : le même piège, à plus grande échelle.
L’enjeu dépasse la conformité légale. C’est surtout protéger ce qui fait votre métier : la manière dont vous qualifiez un prospect, votre grille tarifaire réelle, vos process internes. Une fois passés dans un flux SaaS américain par défaut, ces éléments sont sortis de votre périmètre.
Trois réflexes simples changent la donne : auto-héberger les flux qui touchent à des données sensibles, faire passer un premier filtre par une IA locale avant l’envoi dans le cloud, et garder une cartographie claire de ce qui sort de votre périmètre.
Comment nettoyer un document avant qu’il parte dans une automatisation ?
Apprenez à « nettoyer » les documents avant de les envoyer à l’étranger via vos automatisations. Concrètement : un document brut passe d’abord par une IA locale (Ollama, LM Studio) qui anonymise les noms, supprime les coordonnées, synthétise le contenu. Seule la version nettoyée part ensuite dans Make ou Zapier. La donnée brute reste chez vous.
Gain typique : la donnée brute ne quitte jamais votre poste
Pour un cabinet libéral qui automatise sa gestion de mails clients : le mail entrant passe d’abord par une IA locale qui extrait les éléments nécessaires (nature de la demande, urgence, sujet), anonymisés. C’est cette synthèse, sans nom ni coordonnée, qui part dans le workflow Make pour création de tâche. Le mail original reste sur votre boîte, jamais expédié vers un serveur tiers.
Ollama tourne sur un Mac ou un PC récent, gratuitement. LM Studio offre une interface plus accessible. Pour un usage TPE, des modèles comme Llama 3.1, Mistral 7B ou Qwen 2.5 suffisent largement à des tâches d’extraction et de résumé sur documents standards.
Quel outil choisir entre Zapier, Make, n8n et l’IA locale ?
Le bon outil dépend du niveau de sensibilité des données qui transitent. Zapier pour les automatisations simples sans données critiques. Make pour les flux complexes, toujours sur données peu sensibles. n8n auto-hébergé pour tout ce qui touche au savoir-faire ou aux clients. Et une IA locale en premier passage dès que vous avez un doute.
Zapier (Zapier Inc., USA)
- Force : interface la plus accessible, 7000+ intégrations, parfait pour démarrer
- Prix : gratuit jusqu’à 100 tâches/mois · 19,99 $/mois Starter · grimpe vite à l’échelle
- Pour qui : automatisations simples sans données critiques, structures qui débutent
Make (Celonis, République tchèque)
- Force : éditeur visuel par scénarios, très bon rapport puissance/prix, serveurs UE disponibles
- Prix : gratuit jusqu’à 1000 opérations/mois · 9 €/mois Core · 16 €/mois Pro
- Pour qui : flux multi-étapes, conditions et branchements, équipes qui acceptent un peu de courbe
n8n self-hosted (n8n GmbH, Allemagne)
- Force : open source, auto-hébergeable sur vos serveurs, intègre nativement l’IA, le plus flexible
- Prix : gratuit en self-hosted (coût serveur ~5-20 €/mois) · 20 €/mois n8n Cloud managé UE
- Pour qui : données sensibles, savoir-faire propriétaire, structures qui veulent garder la main
Ollama / LM Studio (Ollama Inc. · LM Studio AI)
- Force : IA qui tourne 100 % en local, premier passage anonymisation/synthèse avant flux cloud
- Prix : gratuit · investissement = un poste avec 16-32 Go RAM, idéalement Mac M1/M2 ou GPU récent
- Pour qui : pré-traitement systématique des documents avant envoi dans une automatisation
Quels sont les pièges à éviter sur l’automatisation no-code ?
Trois pièges reviennent systématiquement : connecter ses outils sans réfléchir au routage des données, créer des flux que personne ne maintient, pousser le no-code au-delà de sa zone de confort. Le quatrième, plus discret, est de croire qu’une automatisation économique l’est aussi sur le moyen terme : sans monitoring, un flux qui casse en silence peut coûter plus qu’il ne fait gagner.
Bonnes pratiques d'automatisation
- Auto-héberger les flux qui touchent à des données sensiblesn8n self-hosted ou n8n Cloud UE
- IA locale en premier passageOllama ou LM Studio pour anonymiser avant envoi cloud
- Monitoring actif des fluxalerte si un workflow tombe en panne
- Documenter chaque fluxnom, déclencheur, données traitées, propriétaire
- Démarrer par une tâche répétée 10× par semaine minimumROI mesurable
À éviter en premier
- Tout connecter à Zapier sans réfléchir au routage des données
- Données clients ou contrats dans des flux SaaS US par défautRGPD + savoir-faire
- Automatisations fragiles sans maintenance ni monitoring
- Vouloir automatiser une logique métier complexe sans développeur
- Tester l'IA dans le flux sur une donnée critique sans pré-traitement local
Le piège du « tout est possible » est réel. Avec Make et n8n, on peut techniquement reproduire un petit ERP (progiciel de gestion intégré). Mais dès que la logique métier devient complexe, ou qu’il faut intégrer un système sans API publique, vous touchez les limites du no-code. Mieux vaut un développeur sur 1 jour que trois semaines à bricoler un flux qui cassera au premier changement.
L’autre piège plus subtil : la fragilité silencieuse. Un workflow qui tombe en panne sans alerte peut passer inaperçu pendant des jours. Pendant ce temps, les leads ne sont plus créés, les factures ne partent plus, les notifications ne sont plus envoyées. Le coût caché d’une automatisation mal monitorée dépasse souvent le gain de temps initial.
Comment démarrer une automatisation pertinente sans se piéger ?
Tout est possible — il faut juste un process réfléchi et adapté à votre situation pour protéger vos données. L’automatisation n’est pas l’ennemi, c’est l’absence de process qui l’est. Démarrez par identifier une tâche manuelle que vous faites au moins 10 fois par semaine, sans données ultra-sensibles, et qui se branche sur deux applications déjà disponibles dans Zapier ou Make.
Cartographiez d’abord ce qui existe : quelles tâches répétitives ? Quelles données circulent ? Lesquelles sont sensibles (clients identifiables, contrats, savoir-faire) versus non-sensibles (agenda, notifications internes, données publiques) ? Cette cartographie en une page conditionne tout le reste — sans elle, vous automatisez à l’aveugle.
Choisissez ensuite votre première brique. Pour démarrer sans risque : une automatisation non-sensible (notification d’agenda, mise à jour d’un tableur partagé, formulaire de contact vers e-mail), testée sur Zapier gratuit ou Make gratuit. Vous mesurez le temps réellement gagné après 2 semaines avant de vous engager sur un abonnement.
Pour le second flux, dès qu’une donnée plus sensible entre en jeu, basculez sur n8n auto-hébergé ou ajoutez un pré-traitement par IA locale. C’est là que le saut qualitatif se fait : vous passez d’une automatisation tactique à une infrastructure cohérente avec votre niveau d’exigence métier.
Questions fréquentes
Quelle différence entre Zapier, Make et n8n ?
Zapier : le plus simple, idéal pour des automatisations basiques. Make : plus visuel et puissant pour des flux complexes, meilleur rapport qualité-prix. n8n : open source, auto-hébergeable sur vos serveurs, intègre l’IA nativement. Plus le contrôle des données est critique, plus n8n self-hosted prend l’avantage.
Peut-on faire passer des données sensibles dans une automatisation no-code ?
Oui mais avec précaution. Les données qui transitent par Zapier ou Make passent souvent par des serveurs américains. Pour les contrats, fiches clients identifiantes ou savoir-faire propriétaire, privilégiez n8n auto-hébergé ou un pré-traitement par IA locale (Ollama, LM Studio) avant l’envoi dans le flux cloud.
Pourquoi utiliser une IA locale avant une automatisation cloud ?
Pour anonymiser ou synthétiser un document directement sur votre poste, avant qu’il ne parte dans une automatisation SaaS américaine. Ollama ou LM Studio tournent en local, gratuitement, sans transit réseau. La donnée brute reste chez vous, seule la version nettoyée alimente le workflow.
Faut-il auto-héberger n8n soi-même ?
Auto-hébergé sur votre serveur ou un cloud français, n8n garantit que les données ne quittent pas votre périmètre. Sans compétence interne, n8n Cloud (offre managée européenne) est un compromis. L’auto-hébergement complet demande une demi-journée de mise en place et une maintenance légère mensuelle.
Quelle est la première automatisation à mettre en place dans une TPE ?
Une tâche manuelle répétée au moins 10 fois par semaine, sans données ultra-sensibles. Exemple typique : nouvelle réservation Calendly vers fiche CRM, formulaire de contact vers e-mail interne plus tâche. Vous testez gratuitement avec Zapier avant de vous engager sur un outil plus puissant.
Et maintenant ?
Automatiser sans coder en 2026 ne demande ni budget colossal ni équipe technique. Cela demande un process simple : cartographier les tâches, trier sensible et non-sensible, choisir l'outil selon le niveau de criticité, ajouter une IA locale en premier passage dès que vos données métier entrent dans le flux. L'automatisation n'est pas l'ennemi du savoir-faire — c'est l'absence de process qui l'est.
Question à se poser cette semaine : quelle tâche manuelle répétez-vous au moins 10 fois, et quelle donnée circulerait dans le flux si vous l’automatisiez aujourd’hui ?